Caching
Session state works well within a given session. But what if:
- You have long running functions, that're slowing down your app, and you want to run them only once across reruns.
- You want to persist objects across sessions.
Streamlit lets you tackle both issues with its built-in caching mechanism. It provides two decorators to cache a function:
@st.cache_data@st.cache_resource
@st.cache_data
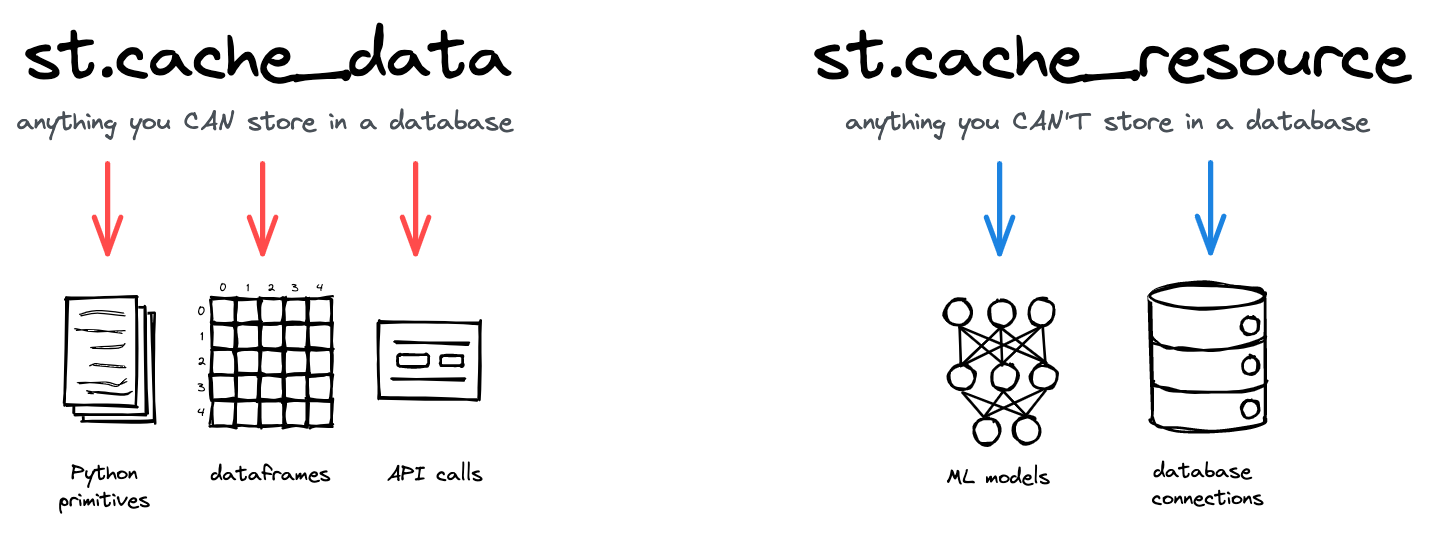
st.cache_data is your go-to command for all functions that return data – whether DataFrames, NumPy arrays, str, int, float, or other serializable types. It caches data within a user's session.
@st.cache_data # 👈 Add the caching decorator
def load_data(url):
df = pd.read_csv(url)
return df
df = load_data("https://github.com/plotly/datasets/raw/master/uber-rides-data1.csv")
st.dataframe(df)
st.button("Rerun")In the above example, if the caching (decorator) wasn't used, the load_data function would have rerun each time the app is loaded or with user interaction (button click). If this function takes significant amount of time, these refreshes would become a poor experience for your users.
With the addition of the decorator, the function is called only once on the first run and is cached for subsequent runs, making them almost instant.
WARNING
st.cache_data implicitly uses the pickle module, which is known to be insecure. Anything your cached function returns is pickled and stored, then unpickled on retrieval. So, you should ensure that only trusted data is loaded, as malicious pickle data can execute arbitrary code during unpickling.
Streamlit checks two things before retrieving a cached result (this applies to st.cache_resource as well):
- The values of the input parameters (in the above example
url) - The code inside the function
If the function is called with same parameters and code more than once, Streamlit skips the function execution and returns the cached result instead.
@st.cache_resource
Unlike st.cache_data which is session-specific, st.cache_resource is used to cache objects that should be available "globally" across all users, sessions and reruns. It has more limited use cases than st.cache_data, especially for caching database connections and ML models.
NOTE
st.cache_data is session-scoped, while st.cache_resource is global.
Also, unlike st.cache_data, which uses the pickle module, st.cache_resource can cache any object regardless of its pickle-serializability, making it the only option for non-serializable objects.
st.cache_resource is very useful for caching ML models or database connections. Creating a new DB connection on every run would be inefficient and can lead to connection errors.
import streamlit as st
@st.cache_resource
def init_connection():
host = "hh-pgsql-public.ebi.ac.uk"
database = "pfmegrnargs"
user = "reader"
password = "NWDMCE5xdipIjRrp"
return psycopg2.connect(host=host, database=database, user=user, password=password)
conn = init_connection()In the above example, without the decorator, a new database connection object would have been created on every rerun.
Differences between caching decorators
st.cache_datais session-scoped, whilest.cache_resourceis global.st.cache_datacan also cache the functions whose return values are serializable. Forst.cache_resource, the return values need not be serializable, e.g.,database connections, ML models, file handles, threads etc.st.cache_resourcedoes not create a copy of the cached return value but instead stores the object itself in the cache. All mutations on the function's return value directly affect the object in the cache, so you must ensure that mutations from multiple sessions do not cause problems. In short, the return value must be thread-safe.
WARNING
Using st.cache_resource on objects that are not thread-safe might lead to crashes or corrupted data.
- Also, not creating a copy means there's just one global instance of the cached return object, which saves memory, e.g. when using a large ML model.
Excluding input parameters
In a cached function, all input parameters must be hashable. By default, Streamlit hashes the input parameters of a cached function, to compare them across function calls. However, not all parameters are hashable, e.g., database connection, ML models etc. In such cases, you can choose to exclude the parameter from caching. To achieve this, simply prepend the parameter name with an underscore (e.g., _param1). Even if it changes, Streamlit will return a cached result as long as all other parameters remain the same.
@st.cache_data
def fetch_data(_db_connection, num_rows): # 👈 Don't hash _db_connection
data = _db_connection.fetch(num_rows)
return data
connection = init_connection()
fetch_data(connection, 10)Parameters
ttl
The ttl (time-to-live) paramater sets the lifespan of a cached function. If the time is up and you call the function again, the app will discard any old cached values and re-executes the function.
This behavior is useful for preventing stale data, for example, when caching database query results, and for preventing the cache to grow too large.
@st.cache_data(ttl=3600) # 👈 Cache data for 1 hour (=3600 seconds)
def get_api_data():
data = api.get(...)
return dataTIP
You can also set ttl values using timedelta, e.g., ttl=datetime.timedelta(hours=1).
max_entries
The max_entries parameter sets the number of entries in the cache. An upper bound on the number of cache entries is useful for limiting memory, especially when caching large objects. When the cache is full, the oldest entry will be removed to make room for the new one.
@st.cache_data(max_entries=1000) # 👈 Maximum 1000 entries in the cache
def get_large_array(seed):
np.random.seed(seed)
arr = np.random.rand(100000)
return arrshow_spinner
By default, Streamlit shows a small loading spinner in the app when a cached function is running. You can modify it easily with the show_spinner parameter.
@st.cache_data(show_spinner=False) # 👈 Disable the spinner
def get_api_data():
data = api.get(...)
return data
@st.cache_data(show_spinner="Fetching data from API...") # 👈 Use custom text for spinner
def get_api_data():
data = api.get(...)
return datahash_funcs
If you don't want to ignore unhashable input parameters in a cache function, you can use hash_funcs parameter to specify a custom hashing function.
import streamlit as st
class MyCustomClass:
def __init__(self, initial_score: int):
self.my_score = initial_score
def hash_func(obj: MyCustomClass) -> int:
return obj.my_score # or any other value that uniquely identifies the object
@st.cache_data(hash_funcs={MyCustomClass: hash_func})
def multiply_score(obj: MyCustomClass, multiplier: int) -> int:
return obj.my_score * multiplier
initial_score = st.number_input("Enter initial score", value=15)
score = MyCustomClass(initial_score)
multiplier = 2
st.write(multiply_score(score, multiplier))For more examples of hash_funcs, refer this section of the official docs.
Static elements
Since version 1.16.0, cached functions can contain Streamlit commands! For example, you can do this:
@st.cache_data
def get_api_data():
data = api.get(...)
st.success("Fetched data from API!") # 👈 Show a success message
return dataAs we know, Streamlit runs this function only if it hasn't been cached yet. On this first run, the st.success message will appear in the app. But what happens on subsequent runs? It still shows up! Streamlit realizes that there is an st. command inside the cached function, saves it during the first run, and replays it on subsequent runs. Replaying static elements works with both caching decorators.
Input Widgets
You can also use interactive input widgets like st.slider or st.text_input in cached functions. Widget replay is an experimental feature at the moment. To enable it, you need to set the experimental_allow_widgets parameter:
@st.cache_data(experimental_allow_widgets=True) # 👈 Set the parameter
def get_data():
num_rows = st.slider("Number of rows to get") # 👈 Add a slider
data = api.get(..., num_rows)
return dataNOTE
st.file_uploader and st.camera_input widgets are not supported in cached functions.